As I have been writing more consistently, I’ve discovered some substantial use cases for selectively using AI in my writing process. I don’t have an interest in AI for the writing itself, but it is far more efficient with the Information Architecture of my writing and some quality control checks where I’ve been too close to the material. This post will dive into how I used Claude Code to overhaul my categories and tags systems, how future posts get taxonomy terms added to them, and quality checks I’ve implemented as part of my publication process.
Writing Information Architecture is Hard
I started writing the first iteration of this blog way back in 2017. I was working in Facilities Management at the time and was trying to switch careers while still working full time. It was a stressful 15 months, but the process changed the trajectory of my life. I had limited experience writing a blog before then, but I knew having posts in a respective category and with corresponding tags was beneficial with the discoverability of new content. As I continued writing over the next few years I’d add tags here and there, but there wasn’t much strategy behind it. Some tags only applied to one post, and the categories were way too broad. While my goal was good in concept, the execution was pretty horrible. Pattern matching is one of my greatest strengths, but something about this particular flavor of pattern creation pinned those skills down.
In 2023, I spun up a different blogging platform to house more of my social, ethical, and gender theory meets reality posts. I wanted to keep those separate from the technical posts at the time. These posts had slightly better categorization, but there were far fewer of them. After I merged the two writing platforms into a brand new one, I knew that I wanted to revisit this overall issue to provide better discoverability of content. The problem was that I had a mess of an existing system, and still lacked the skills to clean up and refine it. This is laughably apparent by the inability to even capture all of the tags in one screenshot. Somehow I had accummulated 105 tags! 😱



Putting Claude to Work to Overhaul my System
With my positive experiences using Claude to do the systems migration into the current iteration, I decided to try out having it suggest and implement a review of the current system. My goals included:
- Clean up and consolidate tags that are duplicative and redundant.
- Go through all of the existing content, apply existing tags where applicable and create new tags if they could be used by more than one post.1
- Review all of the current tags again, and clean up tags that weren’t helpful or were only used once. This process was started with Claude and finished manually.
- Start fresh and recommend a new means of categorizing content based on the existing catalog. Some of the previous categories may transfer over, but if they all get revamped that was fine.
I got to work writing some prompts and cranking through the roughly 70 posts of content already in the system. Reading Markdown files and parsing frontmatter consistently is a time consuming and expensive process. As the system got refined, I took advantage of Claude’s memory management and created JSON files for the category and tag taxonomy respectively. Claude also took advantage of this format to store the new systems for future posts before the existing ones were migrated. Equipped with a new data structure, it was time to migrate all of the things. The raw numbers are:
- Tags reduced from 105 to 47. This was a total reduction of 55% of cruft in the system. While there are a few tags remaining with a single post, they are intentionally left to align with future writing plans.
- Categories increased by a factor of three from 3 to 9. This resolved the opposite problem where there was insufficient granularity on topics. This allows better grouping of topics for individuals to find related content.


Automating Taxonomy for new Posts
Getting the existing system cleaned up and renovated was a great step in the overall problem. However, it would be naïve to think that the overall systems issue had been solved. How do I make sure that I consistently adhere to this for new content? How do I reduce the friction of handling taxonomy so that I can focus on the writing that I actually enjoy? Also, how do I allow for new tags to be created without having a bunch of one off tags? In the vernacular of an engineering lead, I had helped to mitigate an active incident, but needed to further address the underlying whys to help reduce the likelihood of reintroducing this degraded experience.
Thankfully, the foundation was already set from the overhaul and migration process. I had taxonomy JSON files which could be referenced and updated for more performant operations. I created a Blog Taxonomy Guide file that could be loaded into memory and provide a standardized means of applying categories and tags to future posts. This initially mirrored the process of the initial migration. However, as I continued to review the work I noticed some odd and undesirable behaviors.
Initially, all tags were converted to a standard Title Case. This created issues with technical terms which require capitalization in alternate locations or are abbreviations (ex: GraphQL, CSS, TypeScript, etc). Those were lost both in the original source files and on the tags page. I updated the prompt to fix these values and persisted in the Markdown file to not standardize the casing for technical terms to avoid future issues.
With those adjustments, the first iteration of the automated approach for adding taxonomy terms to new posts was ready for use. After I completed the writing of The Polarity of Identity Work last week, it was time to test things in action. The prompt was simple and direct to test if the memory management worked as expected. “Please analyze content/posts/the-polarity-of-identity-work.md and suggest a category and tags for the post”. A few seconds later, I was able to review the suggested taxonomy terms for the post.

Quality Checks Prior to Publication
The work of an engineer never ends. As we gather more inputs and outputs, it’s common to find tweaks and optimizations to make to existing systems. As I was reviewing some search results for the updated site, I noticed that the generic site description was showing up for many of the posts which had been indexed. After some digging into the templating syntax, I discovered that this logic was a fallback in case a page didn’t implement a description or summary property. Generic site descriptions were unacceptable for a writing platform and the next round of mitigation and prevention measures began.
Both properties are valid to use on a page, but my current template will print out the description underneath the first heading if it is present. Pragmatically, this serves as a sub-header to an end user. Sometimes that is desired, and other times, I want to only surface the summary as meta information for SEO, open-graph cards, etc. I set out to update all of the existing content before updating my automation tasks.
- Review all of the markdown files.
- If there is a
descriptionproperty in the YAML frontmatter with a value, leave the file as is. This early exit condition handled my explicit setting of a description to display with the post. - Otherwise, create a
summaryproperty. Scan the content of the post, and write up a SEO friendly summary not to exceed 160 characters.
The initial process of the 70 backlogged posts took a few minutes, including some tweaking of the output. A few posts incorrectly had the description replaced with a summary key. Overall, it was a quick solution to rectify some poor SEO practices.
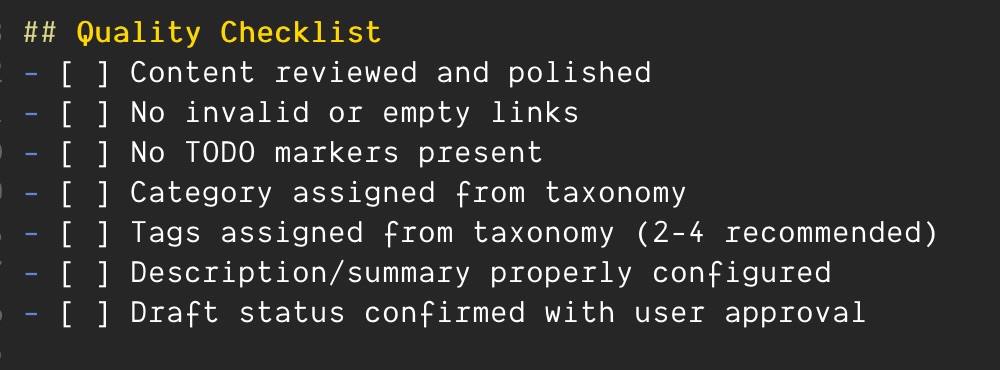
With the latest issue captured and a growing complexity of steps to verify that a post was ready for publication, it was time to create another memory file for future use to prepare a post for publication. The proper handling of taxonomy was only part of the equation. The latest iteration runs through the following steps for a consistent editorial review:
- Review the content for proper links and any references of
TODOwithin the post. This is a common pattern I use during the first draft process to avoid getting bogged down in small details. However, I don’t want to post something with invalid links or items still in need of clarification. - Add the category and tags as captured in the previously mentioned taxonomy file.
- Review the post and add a
summaryif there is no existing description. - Check if the post is still marked as a draft. If it is, ask for user input to change that to false.2
Time will tell how this continues to evolve. This post will be the first to undergo the latest iteration. However, the initial experience of reducing my cognitive load for adding a category and tags to a post has already had phenomenal dividends. A computer is much better at grouping together content; this allows me to focus on writing new content.
My overall intention was to remove one off tags. However, some single use tags were strategically left due to their alignment with short-term writing plans. It’s a general guideline rather than a hard rule. ↩︎
My current build step has multiple guards for publishing a post in production builds. If a post is marked as a draft it will never be included in a production build. If the post is not a draft, but has a
publishDatein the future, it will also be excluded from a build. This enables me to work on future posts locally as well as queue up posts that are ready to publish on their respective dates. ↩︎